No Capítulo 3, dedicamo-nos à modelagem de fenômenos espaciais estáticos, onde a variável regionalizada \(Y(\mathbf{s})\) era tratada como uma “fotografia” instantânea de um processo num tempo fixo \(t_0\). Contudo, a realidade raramente é estática. Fenômenos ambientais, como a dispersão de poluentes atmosféricos, a propagação de doenças ou a dinâmica de chuvas, evoluem simultaneamente no espaço e no tempo.
Este capítulo expande o que foi visto no Capítulo 3, para o domínio espaço-temporal. O objeto de estudo deixa de ser uma superfície estática para se tornar um processo dinâmico estocástico \(Y(\mathbf{s}, t)\). O objetivo central desloca-se da interpolação espacial pura para a previsão do comportamento do fenômeno em locais não monitorados e instantes futuros, integrando a autocorrelação espacial com a dinâmica temporal (Cressie e Wikle 2011).
7 Conceitos básicos
A Geoestatística espaço-temporal generaliza a teoria das variáveis regionalizadas para o domínio misto \(D \times T\), onde \(D \subseteq \mathbb{R}^d\) representa o domínio espacial e \(T \subseteq \mathbb{R}\) o domínio temporal.
Definimos um Campo Aleatório Espaço-Temporal (ou Processo Estocástico) como uma coleção de variáveis aleatórias:
\[\{Y(\mathbf{s}, t) : \mathbf{s} \in D, t \in T\}\]
Onde \(Y(\mathbf{s}, t)\) representa o valor do processo na localização \(\mathbf{s}\) e no instante \(t\).
Ao contrário da geoestatística puramente espacial, onde a ordenação dos dados em \(\mathbb{R}^2\) não é natural, a componente temporal introduz uma ordenação intrínseca e uma causalidade (o passado influencia o futuro, mas não o inverso). Kyriakidis e Journel (1999) classificam as abordagens de modelagem em duas categorias principais:
Vetores de séries temporais: Onde o foco é a dinâmica temporal em locais discretos.
Campos aleatórios contínuos: Onde espaço e tempo são tratados como um continuum unificado, permitindo a definição de covariâncias conjuntas \(C(\mathbf{h}, u)\), onde \(\mathbf{h}\) é a separação espacial e \(u\) é a separação temporal.
A grande vantagem desta segunda abordagem, adotada aqui, é a capacidade de realizar Krigagem Espaço-Temporal, permitindo prever valores em qualquer coordenada \((\mathbf{s}_0, t_0)\) do domínio contínuo, preenchendo lacunas de dados de sensores e prevendo estados futuros.
7.1 Escala e a Anisotropia
A transição do espaço para o espaço-tempo introduz um desafio de incomensurabilidade das unidades. No caso puramente espacial, as coordenadas \(x\) e \(y\) são isotrópicas ou geometricamente ajustáveis, pois ambas representam distâncias físicas (metros). No domínio espaço-temporal, estamos a tentar medir a “distância” entre dois pontos \(A=(\mathbf{s}_i, t_k)\) e \(B=(\mathbf{s}_j, t_l)\) cujas unidades são heterogêneas (metros vs. segundos/dias).
Como definir se o ponto \(A\) está próximo de \(B\)? Uma distância euclidiana simples \(\sqrt{\|\mathbf{h}\|^2 + u^2}\) não faz sentido físico, pois soma metros quadrados com segundos quadrados.
Para resolver este problema, a literatura propõe tratar o tempo como uma dimensão espacial adicional, mas redimensionada por um fator de velocidade. Gr"aler, Pebesma, e Heuvelink (2016) e Gneiting (2002) formalizam isso através de uma métrica espaço-temporal ajustada. A distância espaço-temporal \(d_{ST}\) entre dois pontos separados por um lag espacial \(\mathbf{h}\) e um lag temporal \(u\) é definida como:
Onde \(\kappa\) é um parâmetro de conversão de unidades (velocidade média característica do fenômeno), que transforma unidades de tempo em unidades de espaço (ex: \(m/s \cdot s = m\)). Este parâmetro torna o tempo equivalente ao espaço, permitindo o uso de modelos de variograma estacionários em \(\mathbb{R}^{d+1}\). A estimação correta de \(\kappa\) é crucial; se \(\kappa \to 0\), o tempo torna-se irrelevante (processo puramente espacial repetido); se \(\kappa \to \infty\), o espaço torna-se irrelevante.
7.2 Análise Exploratória de Dados Espaço-Temporais (ST-ESDA)
Antes de ajustar modelos de covariância complexos, é imperativo compreender a estrutura dinâmica dos dados. A Análise Exploratória de Dados Espaciais (ESDA), vista no Capítulo 3, evolui aqui para ST-ESDA (Spatio-Temporal Exploratory Data Analysis).
Utilizaremos o conjunto de dados air (qualidade do ar na Alemanha) do pacote spacetime para ilustrar estas técnicas.
Os dados espaço-temporais no R são frequentemente geridos por estruturas específicas que organizam a geometria espacial e o índice temporal. O pacote spacetime(Pebesma 2012) fornece a classe STFDF (Space-Time Full Data Frame), ideal para esta tarefa.
Código
if (!require("pacman")) install.packages("pacman")pacman::p_load(spacetime, gstat, ggplot2, viridis, dplyr, sf, lubridate, ragg)data(air) # air_st é um objeto STFDF (Space-Time Full Data Frame)# Contém:# - sp: geometria das estações (SpatialPoints)# - time: datas das observações# - data: medições de PM10rural =STFDF(stations, dates, data.frame(PM10 =as.vector(air)))# Convertendo para formato longo (Tidy) para facilitar o uso com ggplot2df_st <-as.data.frame(rural) %>% dplyr::mutate(date =as.Date(time) ) %>% dplyr::rename(PM10 = PM10) %>% dplyr::filter(!is.na(PM10))glimpse(df_st)
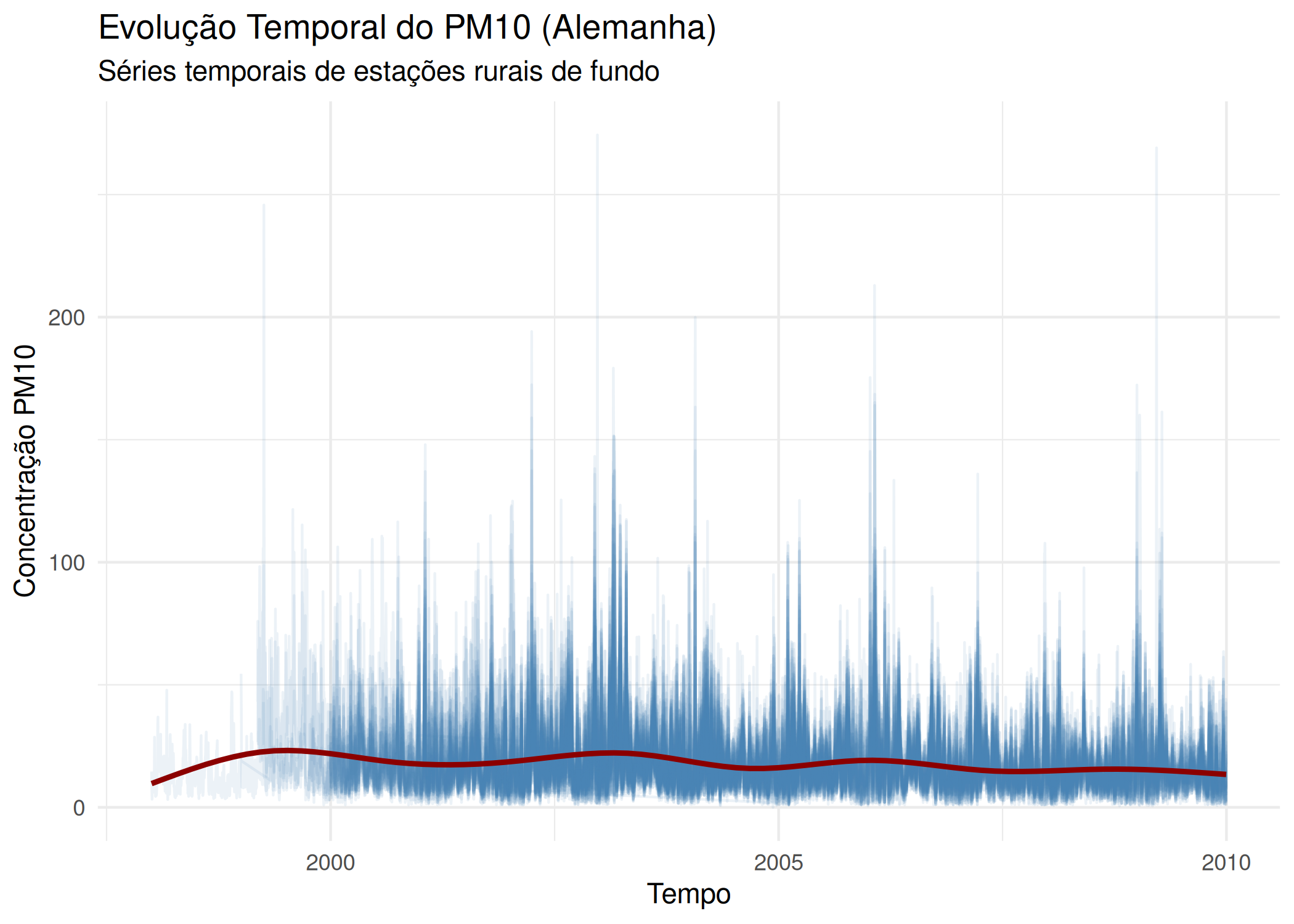
A primeira abordagem visual é inspecionar a evolução temporal de todas as localizações simultaneamente. Este gráfico, conhecido como Spaghetti Plot, permite identificar:
Tendência Global: Se todas as linhas sobem ou descem juntas.
Sazonalidade: Padrões cíclicos anuais ou diários.
Outliers Espaciais: Estações (linhas) que se comportam de forma distinta da “massa” de dados.
Código
ggplot(df_st, aes(x = date, y = PM10, group = sp.ID)) +geom_line(alpha =0.1, color ="steelblue") +geom_smooth(aes(group =1), color ="darkred", se =FALSE, size =1) +labs(title ="Evolução Temporal do PM10 (Alemanha)",subtitle ="Séries temporais de estações rurais de fundo",x ="Tempo", y ="Concentração PM10") +theme_minimal()
Figura 7.1: Spaghetti Plot das concentrações de PM10. Cada linha representa uma estação de monitoramento. A linha vermelha indica a tendência média suavizada.
Diagramas de Hovmöller
Uma das ferramentas mais poderosas na análise espaço-temporal é o Diagrama de Hovmöller. Originalmente desenvolvido na meteorologia, este gráfico colapsa uma das dimensões espaciais (latitude ou longitude) para visualizar o transporte ou propagação de fenômenos ao longo do tempo.
Imagine que temos um poluente a ser transportado por ventos de Oeste para Este. Num gráfico onde o eixo X é o Tempo e o eixo Y é a Longitude, veríamos faixas diagonais de concentração, indicando que o pico de poluição se move para leste à medida que o tempo avança.
Hovmöller Latitude-Tempo: Útil para ver padrões Norte-Sul.
Hovmöller Longitude-Tempo: Útil para ver padrões Leste-Oeste.
Código
# Precisamos das coordenadas lat/long no dataframedf_st <- df_st %>% dplyr::rename(lon = coords.x1,lat = coords.x2,station_id = sp.ID )df_estacoes_media <- df_st %>%group_by(station_id, lon, lat) %>%summarise(PM10_medio =mean(PM10, na.rm =TRUE), .groups ="drop")glimpse(df_estacoes_media)ggplot(df_st, aes(x = date, y = lat, fill = PM10)) +geom_tile() +scale_fill_viridis_c(option ="inferno", name ="PM10") +labs(title ="Diagrama de Hovmöller",subtitle ="Variação Latitudinal ao longo do Tempo",x ="Tempo", y ="Latitude (Norte-Sul)") +theme_minimal() +theme(legend.position ="bottom")
A interpretação da ?fig-hovmoller permite diagnosticar a estacionariedade. Se observarmos faixas verticais claras (cores constantes ao longo de Y para um dado X), significa que o fenômeno ocorre em todo o espaço simultaneamente (apenas dependência temporal). Se virmos manchas localizadas, há forte interação espaço-tempo.
A visualização da sequência de mapas no tempo é também fundamental para entender a difusão do processo. No R, o pacote gganimate facilita esta tarefa.
Dica
A animação permite ao analista perceber intuitivamente o alcance temporal da correlação. Se o mapa “pisca” erraticamente de um dia para o outro, a correlação temporal é baixa. Se as manchas de alta concentração se movem e se dissipam lentamente, a correlação temporal é alta.
Código
pacman::p_load(gganimate, rnaturalearth, gifski,magick)germany <-ne_countries(scale ="medium", country ="Germany", returnclass ="sf")df_subset <- df_st %>%filter(date >=as.Date("2005-01-01") & date <=as.Date("2005-01-31"))anim <-ggplot() +geom_sf(data = germany, fill ="gray95", color ="gray50") +geom_point(data = df_subset, aes(x = lon, y = lat, color = PM10, size = PM10), alpha =0.8) +scale_color_viridis_c(option ="magma") +labs(title ='Data: {frame_time}', x ="Longitude", y ="Latitude") +theme_minimal() +transition_time(date) +ease_aes('linear')animate(anim, nframes =100, fps =10, renderer =gifski_renderer(),width =700, height =500)
7.2.1 Criação da estrutura de dados espaço-temporais no R
A análise de dados espaço-temporais requer estruturas que consigam armazenar, de forma eficiente e integrada, a informação geográfica, a informação temporal e os valores das variáveis de interesse. No ambiente R, o pacote spacetime(Pebesma 2012) estabeleceu o padrão para lidar com este tipo de dados através da classe ST (Space-Time) e suas subclasses.
A classe mais comum e versátil para dados de monitoramento (como estações meteorológicas ou sensores de qualidade do ar) é a STFDF (Space-Time Full Data Frame). Esta classe é ideal quando temos um conjunto fixo de localizações espaciais e, para cada localização, temos observações em todos os instantes de tempo definidos (uma grelha completa espaço-tempo).
Um objeto STFDF é composto por três elementos fundamentais:
Componente Espacial (sp): Um objeto da classe Spatial (do pacote sp ou convertível para tal) que contém as coordenadas geográficas das estações de monitoramento ou pontos de amostragem.
Componente Temporal (time): Um objeto de classe temporal (geralmente xts ou POSIXct) que define os instantes ou intervalos de tempo das observações.
Dados (data): Um data.frame contendo as medições das variáveis. A estrutura deste data frame deve seguir uma ordem específica: os dados devem estar ordenados primeiro pelo tempo e depois pelo espaço (ou vice-versa, dependendo da construção, mas o padrão do spacetime assume uma estrutura longa onde o índice espacial roda mais rápido que o temporal ou o inverso, exigindo consistência).
Importante
Para construir um STFDF corretamente, o vetor de dados deve estar ordenado de forma específica. O spacetime assume que o índice espacial roda mais rápido que o índice temporal. Ou seja, a ordem dos dados deve ser:
Para ilustrar a criação de um objeto STFDF, vamos simular um cenário prático: suponha que temos dados de temperatura recolhidos em 3 estações meteorológicas durante 5 dias consecutivos.
Passo 1: Definir a Componente Espacial
Primeiro, definimos as localizações das estações. Vamos criar um objeto SpatialPoints (do pacote sp) ou sf (do pacote sf e depois converter, ver Seção 2.6).
Código
if (!require("pacman")) install.packages("pacman")pacman::p_load(sp, spacetime, xts)# Criando coordenadas para 3 estaçõescoords <-data.frame(id =c("Estacao_A", "Estacao_B", "Estacao_C"),lon =c(-9.13, -8.62, -7.91),lat =c(38.72, 41.15, 37.02))# Convertendo para SpatialPointssp_points <-SpatialPoints(coords[, c("lon", "lat")], proj4string =CRS("+proj=longlat +datum=WGS84"))
Passo 2: Definir a Componente Temporal
Em seguida, criamos a sequência temporal. O pacote spacetime integra-se bem com objetos de data/hora padrão do R.
Código
# Criando uma sequência de 5 diasdatas <-as.Date("2023-01-01") +0:4
Passo 3: Organizar os Dados
A parte mais crítica é garantir que os dados estejam no formato correto. Para um STFDF, precisamos de \(n \times m\) observações, onde \(n\) é o número de locais espaciais e \(m\) é o número de instantes temporais. Os dados devem ser fornecidos num vetor ou data frame que represente esta grelha completa.
O padrão do construtor STFDF assume que os dados estão ordenados de forma a que o espaço varia primeiro (para cada tempo fixo, temos todos os locais) ou o tempo varia primeiro (para cada local fixo, temos todos os tempos). O argumento data deve ter \(n \times m\) linhas.
Código
set.seed(123)temperatura <-rnorm(15, mean =20, sd =3)# Organizando num data.frame# Importante: A ordem deve ser consistente com a construção do STFDF.# Geralmente: Local 1 (t1, t2, ...), Local 2 (t1, t2, ...), ...# OU Tempo 1 (l1, l2, ...), Tempo 2 (l1, l2, ...)# Vamos criar um data frame expandido para garantir a ordemdf_dados <-expand.grid(time = datas, sp =1:length(sp_points))df_dados$temp <- temperatura # Note que expand.grid roda o primeiro argumento (time) mais rápido. # Então temos: t1-s1, t2-s1, t3-s1... depois t1-s2...# Isso corresponde à ordenação: Estação 1 (todos os tempos), Estação 2 (todos os tempos)...
Passo 4: Criar o Objeto STFDF
Agora unimos tudo usando a função construtora STFDF. É importante notar que a classe STFDF armazena os dados de uma forma eficiente, não repetindo as coordenadas nem as datas para cada observação, mas sim mantendo a estrutura de grelha.
Código
# Construção do objeto STFDF# sp: objeto espacial com 3 pontos# time: vetor de 5 datas# data: data frame com 15 linhas (3 * 5)# A função STFDF espera que o data frame de dados esteja ordenado de forma que# as localizações espaciais girem mais rápido que o tempo, OU SEJA:# (s1,t1), (s2,t1), (s3,t1), (s1,t2), (s2,t2)...# Vamos reordenar nosso df_dados para garantir isso:df_dados_ordenado <- df_dados[order(df_dados$time, df_dados$sp), ]stfdf_obj <-STFDF(sp = sp_points, time = datas, data =data.frame(temp = df_dados_ordenado$temp))summary(stfdf_obj)
Object of class STFDF
with Dimensions (s, t, attr): (3, 5, 1)
[[Spatial:]]
Object of class SpatialPoints
Coordinates:
min max
lon -9.13 -7.91
lat 37.02 41.15
Is projected: FALSE
proj4string : [+proj=longlat +datum=WGS84 +no_defs]
Number of points: 3
[[Temporal:]]
Index timeIndex
Min. :2023-01-01 Min. :1
1st Qu.:2023-01-02 1st Qu.:2
Median :2023-01-03 Median :3
Mean :2023-01-03 Mean :3
3rd Qu.:2023-01-04 3rd Qu.:4
Max. :2023-01-05 Max. :5
[[Data attributes:]]
temp
Min. :16.20
1st Qu.:18.50
Median :20.33
Mean :20.46
3rd Qu.:21.29
Max. :25.15
Uma vez criado, o objeto STFDF pode ser manipulado e visualizado facilmente. Podemos aceder aos dados como se fosse uma matriz (espaço nas linhas, tempo nas colunas) ou usar métodos de plotagem integrados.
Código
stplot(stfdf_obj, main ="Temperatura nas Estações (Simulado)")
A transformação correta para STFDF é um pré-requisito fundamental para a aplicação de métodos de variografia e krigagem espaço-temporal que veremos nas secções seguintes. Uma vez estruturados os dados neste formato, o pacote gstat(Gr"aler, Pebesma, e Heuvelink 2016) consegue reconhecer automaticamente a topologia espaço-temporal para o cálculo do variograma amostral conjunto e posterior krigagem, aplicando a métrica \(d_{ST}\) discutida na Eq. 7.1.
7.3 Estacionariedade no Espaço-Tempo
A hipótese de estacionariedade, fundamental na geoestatística clássica, exige uma reformulação cuidadosa ao transitar para o domínio espaço-temporal. Enquanto no espaço puramente estático assumimos homogeneidade das propriedades estatísticas sob translação espacial, no domínio misto \(D \times T\) enfrentamos a heterogeneidade intrínseca entre as dimensões espacial e temporal.
Definimos um campo aleatório espaço-temporal \(Y(\mathbf{s}, t)\) como estacionário de segunda ordem se satisfizer simultaneamente:
Média constante: A esperança matemática é invariante no espaço e no tempo:
Esta definição implica que a variância do processo é constante e finita (\(C(\mathbf{0}, 0) = \sigma^2 < \infty\)). Contudo, em fenômenos ambientais reais, a média raramente é constante. A temperatura varia com a latitude e a estação do ano; a concentração de poluentes varia com a proximidade de fontes e a hora do dia.
Uma distinção crucial na modelagem espaço-temporal é a possibilidade de estacionariedade parcial. Um processo pode ser estacionário no espaço, mas não no tempo, e vice-versa. Seguindo Kyriakidis e Journel (1999) temos:
Estacionariedade Espacial: Para qualquer instante fixo \(t\), o campo espacial \(\{Y(\mathbf{s}, t) : \mathbf{s} \in D\}\) é estacionário. Isso significa que a estrutura de correlação espacial não muda com o tempo (embora a média possa mudar).
Estacionariedade Temporal: Para qualquer localização fixa \(\mathbf{s}\), a série temporal \(\{Y(\mathbf{s}, t) : t \in T\}\) é estacionária. Isso implica que a estrutura de correlação temporal é a mesma em todos os locais.
A violação destas hipóteses exige a decomposição do processo em componentes determinísticas e estocásticas, isolando a tendência para recuperar um resíduo estacionário.
Modelagem da Tendência Espaço-Temporal
A abordagem padrão para lidar com a não-estacionariedade na média é a decomposição aditiva do processo \(Y(\mathbf{s}, t)\)(Cressie e Wikle 2011):
Onde \(\mu(\mathbf{s}, t)\) é a função média determinística (tendência) e \(R(\mathbf{s}, t)\) é o resíduo estocástico, assumido como estacionário de segunda ordem com média zero. A modelagem correta de \(\mu(\mathbf{s}, t)\) é crítica, pois qualquer estrutura não capturada na tendência contaminará o variograma dos resíduos, enviesando a inferência.
Uma decomposição comum e eficaz para \(\mu(\mathbf{s}, t)\), sugerida por Gr"aler, Pebesma, e Heuvelink (2016), separa as influências puramente espaciais das puramente temporais:
\(m(\mathbf{s})\): Representa a variação espacial sistemática que é constante no tempo. Exemplo: Em dados de temperatura, \(m(\mathbf{s})\) capturaria o efeito da elevação ou da latitude média de cada local. Pode ser estimada pela média temporal em cada local (\(\bar{y}(\mathbf{s}) = \frac{1}{T}\sum_{t=1}^T y(\mathbf{s}, t)\)) ou por regressão com covariáveis espaciais (latitude, elevação).
\(m(t)\): Representa a variação temporal global que afeta todo o domínio espacial simultaneamente. Exemplo: Sazonalidade anual ou tendência de aquecimento global. Pode ser estimada pela média espacial em cada instante (\(\bar{y}(t) = \frac{1}{N}\sum_{i=1}^N y(\mathbf{s}_i, t)\)) ou por funções harmônicas (senos e cossenos para sazonalidade).
\(R(\mathbf{s}, t)\): É o componente residual que contém a interação espaço-temporal e a aleatoriedade local. O objetivo da geoestatística é modelar a covariância deste termo, \(C_R(\mathbf{h}, u)\), assumindo que ele satisfaz a hipótese de estacionariedade.
Nota
Esta decomposição assume aditividade simples. Em casos mais complexos, pode ser necessário incluir termos de interação na tendência, \(\mu(\mathbf{s}, t) = m(\mathbf{s}) + m(t) + m(\mathbf{s}, t)_{int}\), ou utilizar covariáveis dinâmicas (ex: temperatura do ar como preditor de ozônio).
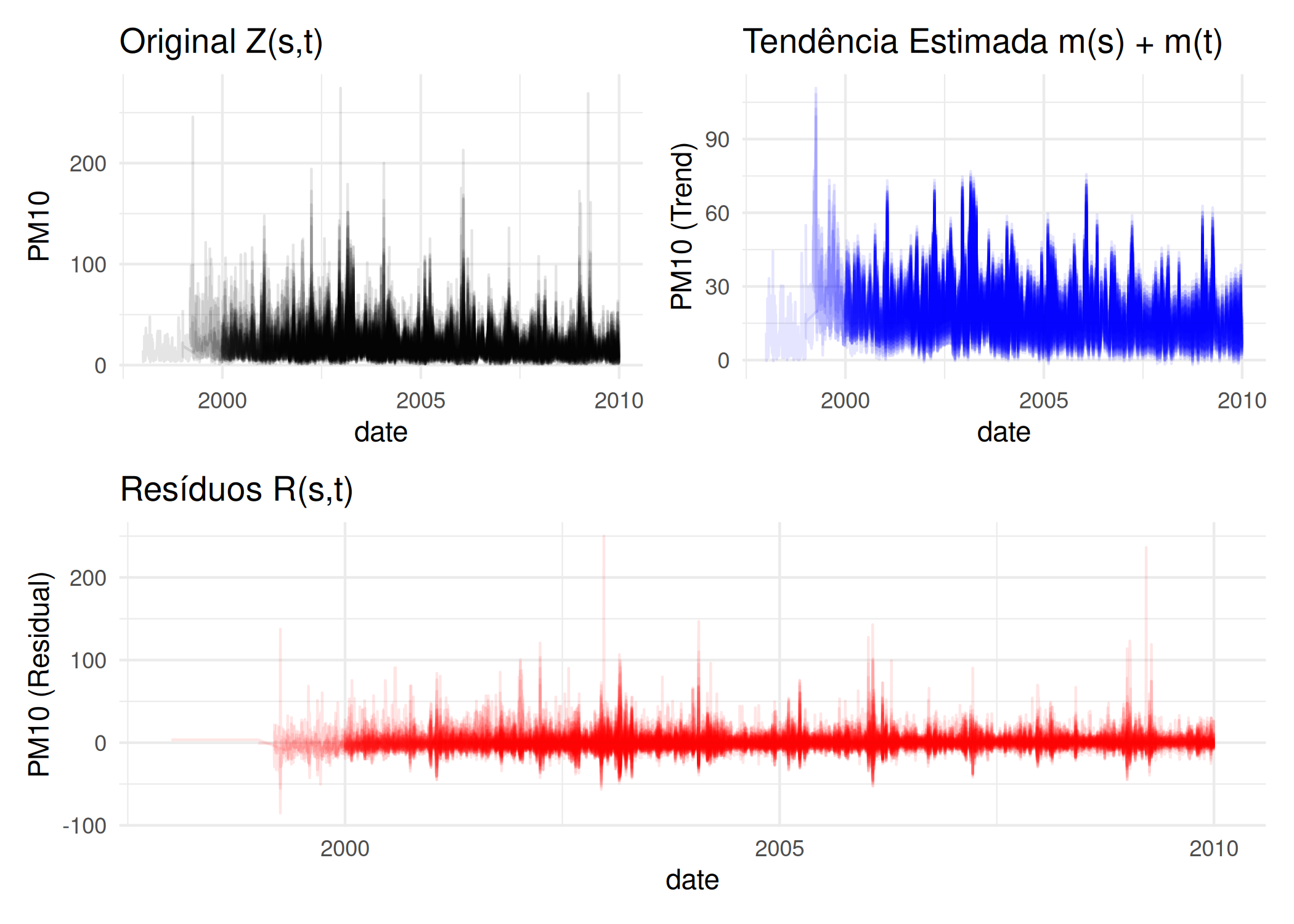
A validação desta decomposição é feita através da análise dos resíduos estimados \(\hat{R}(\mathbf{s}, t) = y(\mathbf{s}, t) - \hat{m}(\mathbf{s}) - \hat{m}(t)\). Se a tendência foi removida com sucesso, o variograma experimental dos resíduos deve estabilizar num patamar claro e não deve exibir tendências sistemáticas no espaço ou no tempo.
Código
pacman::p_load(ggplot2, patchwork, viridis)# Assegurando que os dados estão carregados (do exemplo anterior)df_st <- df_st %>% dplyr::rename(lon = coords.x1,lat = coords.x2,station_id = sp.ID )# Média temporal para cada estaçãom_s <- df_st %>%group_by(station_id) %>%summarise(mean_spatial =mean(PM10, na.rm =TRUE))# Estimativa da Tendência Temporal m(t)global_mean <-mean(df_st$PM10, na.rm =TRUE)m_t <- df_st %>%group_by(date) %>%summarise(mean_temporal =mean(PM10, na.rm =TRUE) - global_mean)# Resíduo R(s, t)df_decomp <- df_st %>%left_join(m_s, by ="station_id") %>%left_join(m_t, by ="date") %>%mutate(trend = mean_spatial + mean_temporal,residual = PM10 - trend )p1 <-ggplot(df_decomp, aes(x = date, y = PM10, group = station_id)) +geom_line(alpha =0.1, color ="black") +labs(title ="Original Z(s,t)", y ="PM10") +theme_minimal()p2 <-ggplot(df_decomp, aes(x = date, y = trend, group = station_id)) +geom_line(alpha =0.1, color ="blue") +labs(title ="Tendência Estimada m(s) + m(t)", y ="PM10 (Trend)") +theme_minimal()p3 <-ggplot(df_decomp, aes(x = date, y = residual, group = station_id)) +geom_line(alpha =0.1, color ="red") +labs(title ="Resíduos R(s,t)", y ="PM10 (Residual)") +theme_minimal()(p1+ p2) / p3
Na ?fig-decomposicao_tendencia, observamos que a componente de tendência captura a variação sazonal forte e as diferenças médias entre estações. Os resíduos resultantes, centrados em zero, são o objeto adequado para a modelagem do variograma espaço-temporal, pois aproximam-se mais da hipótese de estacionariedade exigida.
7.4 Variograma Espaço-Temporal
A análise da estrutura de dependência em processos estocásticos espaço-temporais \(Y(\mathbf{s}, t)\) exige uma generalização do variograma clássico. Contudo, ao contrário da extensão trivial de \(\mathbb{R}^2\) para \(\mathbb{R}^3\), a incorporação da dimensão temporal não pode ser tratada de forma isotrópica com as dimensões espaciais. A natureza física do tempo (unidirecional e com unidades distintas) impõe restrições teóricas que invalidam a simples utilização de um variograma 3D convencional (Kyriakidis e Journel 1999).
Sob a hipótese de estacionariedade intrínseca espaço-temporal, definimos o semivariograma espaço-temporal \(\gamma(\mathbf{h}, u)\) como:
Onde \(\mathbf{h} \in \mathbb{R}^d\) é o vetor de separação espacial e \(u \in \mathbb{R}\) é o intervalo temporal (lag). A modelagem desta função \(\gamma(\mathbf{h}, u)\) é o desafio central da geoestatística espaço-temporal.
Uma abordagem fundamental é decompor a variabilidade total em componentes marginais e interações.
7.4.1 Variogramas Marginais
Os variogramas marginais representam o comportamento do processo quando uma das dimensões (espaço ou tempo) é fixada na origem (lag zero).
Variograma Puramente Espacial (\(\gamma_s(\mathbf{h})\)): Descreve a dependência espacial instantânea (quando \(u=0\)).
\[\gamma_s(\mathbf{h}) = \gamma(\mathbf{h}, 0)\]
Este variograma captura a estrutura espacial média ao longo de todo o período de observação.
Variograma Puramente Temporal (\(\gamma_t(u)\)): Descreve a dependência temporal numa localização fixa (quando \(\mathbf{h}=\mathbf{0}\)).
\[\gamma_t(u) = \gamma(\mathbf{0}, u)\]
Este variograma captura a dinâmica temporal média em todas as localizações espaciais.
A modelagem conjunta requer funções que interpolam validamente entre estes dois extremos, respeitando a condição de definição positiva da função de covariância subjacente.
7.4.2 Modelos de Covariância Espaço-Temporal
A escolha da estrutura da função de covariância \(C(\mathbf{h}, u)\) determina como o modelo trata a interação entre espaço e tempo. O pacote gstat implementa as principais classes teóricas de modelos espaço-temporais, permitindo ajustar a complexidade do modelo à realidade dos dados (Gr"aler, Pebesma, e Heuvelink 2016).
Lembramos que, sob estacionariedade de segunda ordem, a relação entre variograma e covariância é dada por \(\gamma(\mathbf{h}, u) = C(\mathbf{0}, 0) - C(\mathbf{h}, u)\), onde \(C(\mathbf{0}, 0)\) é a variância total do processo (patamar global), ver Seção 3.2.
Modelos Separáveis
A classe mais simples de modelos assume que a estrutura de correlação espaço-temporal pode ser fatorada em componentes puramente espaciais e temporais independentes. Um modelo de covariância é dito separável se puder ser escrito como:
Onde \(\bar{\gamma}\) denota semivariogramas normalizados (com patamar unitário).
A principal vantagem é a eficiência computacional. A matriz de covariância espaço-temporal \(\Sigma_{ST}\) pode ser construída como o Produto de Kronecker das matrizes espacial e temporal (\(\Sigma_S \otimes \Sigma_T\)), o que simplifica a inversão matricial necessária para a krigagem.
Contudo, esta simplificação assume que a estrutura de correlação espacial não muda com o tempo e que a correlação temporal é idêntica em todos os locais. Fenômenos como a difusão ou advecção (vento, correntes) violam esta premissa, pois a correlação espacial tende a decair e espalhar-se ao longo do tempo, o que modelos separáveis não conseguem capturar (Gneiting 2002).
Modelos Produto-Soma
Para superar a rigidez dos modelos separáveis, De Cesare, Myers, e Posa (2001) introduziram a classe Produto-Soma. Esta formulação adiciona flexibilidade permitindo uma mistura entre separabilidade e aditividade:
Este modelo é estritamente não-separável e demonstrou ser eficaz em capturar interações complexas em dados ambientais onde a separabilidade falha, mantendo ainda uma forma analítica tratável.
Modelos Métricos
Os modelos métricos tratam o tempo como uma dimensão espacial adicional, após um reescalonamento adequado para resolver o problema da anisotropia métrica discutido na secção anterior. Assume-se que existe uma única função de covariância isotrópica conjunta \(C_{joint}\) que opera sobre uma distância espaço-temporal \(d_{ST}\):
Onde \(\kappa\) é o parâmetro de anisotropia espaço-temporal que converte unidades de tempo em unidades de distância.
Este modelo garante uma forte interação espaço-tempo, pois uma mudança no tempo é geometricamente equivalente a uma mudança no espaço. É fisicamente intuitivo para processos de difusão simples. No entanto, impõe que a forma funcional da dependência (ex: exponencial, esférica) seja idêntica para o espaço e para o tempo, o que pode ser restritivo se a dinâmica temporal for muito diferente da estrutura espacial (ex: periodicidade no tempo vs. decaimento monótono no espaço).
Modelo Soma-Métrico (Sum-Metric)
O modelo Soma-Métrico representa a abordagem mais robusta e flexível disponível no pacote gstat. Ele combina as vantagens da decomposição aditiva com a interação métrica, permitindo modelar três componentes distintos da variabilidade:
Variabilidade puramente espacial (ex: heterogeneidade do solo persistente).
Variabilidade puramente temporal (ex: tendências globais ou ruído temporal).
Interação espaço-temporal dinâmica.
A função de covariância é definida como a soma de três covariâncias independentes:
Este modelo permite, por exemplo, que a componente espacial tenha um alcance curto e forma esférica, a componente temporal tenha um alcance longo e forma exponencial, e a interação siga um modelo gaussiano com a sua própria anisotropia \(\kappa\). Esta flexibilidade torna-o superior na modelagem de fenômenos complexos, como a qualidade do ar, onde existem fontes fixas de poluição (componente espacial), ciclos diários (componente temporal) e dispersão pelo vento (interação métrica) (Gr"aler, Pebesma, e Heuvelink 2016).
7.4.3 Visualização e Diagnóstico
Uma ferramenta essencial para escolher entre estes modelos é a visualização do variograma amostral como uma superfície ou mapa de calor (Heatmap), onde o eixo X é a distância espacial \(\mathbf{h}\) e o eixo Y é o lag temporal \(u\).
Se as isolinhas de semivariância forem paralelas aos eixos (retangulares), sugere Separabilidade.
Se as isolinhas formarem elipses perfeitas em torno da origem, sugere um modelo Métrico.
Formas mais complexas ou distorcidas indicam a necessidade de modelos Produto-Soma ou Soma-Métrico.
7.4.4 Prática no R
Cálculo do Variograma Espaço-Temporal Experimental
O primeiro passo é calcular a superfície do variograma amostral \(\hat{\gamma}(\mathbf{h}, u)\). Utilizamos a função variogramST.
Código
if (!require("pacman")) install.packages("pacman")pacman::p_load(gstat, spacetime, sp, lattice, viridis)data(air) # Definir projeção para UTM para ter distâncias métricas (em km)rural <-spTransform(rural, CRS("+proj=utm +zone=32 +ellps=WGS84 +units=km"))# Variograma Experimental# width: largura do lag espacial (km)# cutoff: distância espacial máxima (km)# tunit: unidade temporal# tlags: intervalo de lags temporais (0 a 6 dias)v_st <-variogramST(PM10 ~1, data = rural, tunit ="days", width =10, cutoff =200, tlags =0:6)# Eixo X: Distância Espacial (h)# Eixo Y: Lag Temporal (u)plot(v_st, map =TRUE, main ="Mapa de Variograma Espaço-Temporal")
Diagnóstico Visual: Observe o mapa acima.
Se as cores formassem retângulos perfeitos alinhados aos eixos, usaríamos um modelo Separável.
Se as cores formassem arcos elípticos perfeitos, usaríamos um modelo Métrico.
Como vemos uma estrutura mais complexa (a dependência espacial persiste por dias, mas decai), modelos Produto-Soma ou Soma-Métrico são candidatos fortes.
Ajuste dos Modelos Teóricos
A função vgmST define a estrutura do modelo, e fit.StVariogram estima os parâmetros (ver Capítulo 3 para mais detalhes).
Precisamos definir um variograma puramente espacial e um puramente temporal como valores iniciais.
Código
v_space <-vgm(psill =10, model ="Exp", range =50, nugget =2)v_time <-vgm(psill =10, model ="Exp", range =2, nugget =1)# Definição da estrutura Separávelmodel_sep <-vgmST("separable", space = v_space, time = v_time, sill =20)fit_sep <-fit.StVariogram(v_st, model_sep)attr(fit_sep, "MSE")
# Definição da estrutura Produto-Somamodel_ps <-vgmST("productSum", space = v_space, time = v_time, k =5) # k inicial arbitráriofit_ps <-fit.StVariogram(v_st, model_ps, method ="L-BFGS-B")attr(fit_ps, "MSE")
Aqui precisamos definir o parâmetro de anisotropia espaço-temporal stAni (\(\kappa\)). Este parâmetro converte dias em km. Um valor de stAni = 50 significa que 1 dia de decorrência temporal equivale a afastar-se 50 km no espaço em termos de perda de correlação.
Código
# Definimos apenas um variograma conjunto (joint)v_joint <-vgm(psill =20, model ="Exp", range =100, nugget =2)model_met <-vgmST("metric", joint = v_joint, stAni =50) # Palpite inicial: 1 dia ~ 50 kmfit_met <-fit.StVariogram(v_st, model_met)attr(fit_met, "MSE")
Podemos visualizar como cada modelo teórico se ajusta aos pontos experimentais.
Código
plot(v_st, fit_sm, wireframe =TRUE, all =TRUE, scales =list(arrows =FALSE),zlab ="Gama", xlab ="Distância (km)", ylab ="Tempo (dias)",main ="Ajuste do Modelo Soma-Métrico")
7.5 Krigagem Espaço-Temporal
A Krigagem Espaço-Temporal generaliza o sistema de predição linear ótimo para o domínio contínuo \(\mathbb{R}^d \times \mathbb{R}\). O objetivo é estimar o valor da variável regionalizada \(Y(\mathbf{s}_0, t_0)\) numa localização espacial \(\mathbf{s}_0\) e num instante temporal \(t_0\) não observados, utilizando a informação disponível de um conjunto de \(N\) observações distribuídas no espaço e no tempo, \(\mathbf{y} = \{y(\mathbf{s}_i, t_i) : i=1, \dots, N\}\).
A formulação é idêntica à da krigagem espacial clássica (ver Seção 3.13), com a diferença fundamental de que o vetor de covariâncias e a matriz de redundância agora incorporam a dependência temporal através dos modelos de covariância espaço-temporal \(C_{ST}(\mathbf{h}, u)\) ou variogramas \(\gamma_{ST}(\mathbf{h}, u)\) definidos na Seção 7.4.
Sistema de Krigagem ST
O preditor de Krigagem Espaço-Temporal Ordinária \(\hat{Y}(\mathbf{s}_0, t_0)\) é dado por uma combinação linear ponderada:
Onde os pesos \(\lambda_i\) são obtidos minimizando a variância do erro de predição \(\sigma_E^2(\mathbf{s}_0, t_0) = E[(\hat{Y}(\mathbf{s}_0, t_0) - Y(\mathbf{s}_0, t_0))^2]\), sujeitos à restrição de não enviesamento \(\sum \lambda_i = 1\) (assumindo média local desconhecida mas constante no espaço-tempo).
Isso resulta no sistema de equações lineares \(\mathbf{A}_{ST} \mathbf{x}_{ST} = \mathbf{b}_{ST}\)(Kyriakidis e Journel 1999):
\(\mathbf{\Sigma}_{ST}\) é a matriz de covariância espaço-temporal (\(N \times N\)) entre todos os pares de observações. O elemento \((i,j)\) é \(C_{ST}(\mathbf{s}_i - \mathbf{s}_j, t_i - t_j)\).
\(\mathbf{c}_{ST}\) é o vetor de covariâncias (\(N \times 1\)) entre cada observação e o ponto alvo \((\mathbf{s}_0, t_0)\).
\(\nu\) é o multiplicador de Lagrange.
O vetor de dados \(\mathbf{y}\) agora pode ser massivo. Se tivermos \(N_s\) estações monitorando por \(N_t\) instantes de tempo, o tamanho total do sistema é \(N = N_s \times N_t\). A inversão da matriz \(\mathbf{\Sigma}_{ST}\) tem complexidade cúbica \(\mathcal{O}(N^3)\). Para grandes bases de dados, métodos como a krigagem com vizinhança local móvel ou aproximações de baixo posto (SPDE, Fixed Rank Kriging) tornam-se essenciais (Cressie e Wikle 2011).
Tipos de Predição
No domínio espaço-temporal, a localização do ponto alvo \(t_0\) em relação aos dados observados \(\{t_1, \dots, t_N\}\) define diferentes problemas de inferência (Wikle, Zammit-Mangion, e Cressie 2019):
Interpolação: O instante \(t_0\) está dentro do intervalo de tempo amostrado \([\min(t_i), \max(t_i)]\). Usado para preencher falhas em séries temporais (imputação de dados) ou para gerar mapas históricos contínuos (hindcasting).
Previsão (Forecasting): O instante \(t_0\) está no futuro (\(t_0 > \max(t_i)\)). A krigagem utiliza a estrutura de correlação temporal para projetar o estado do sistema. A incerteza (\(\sigma_E^2\)) aumenta rapidamente à medida que \(t_0\) se afasta da última observação.
Para limitar o custo computacional e garantir a relevância local, a krigagem é frequentemente realizada utilizando apenas um subconjunto de dados vizinhos. No espaço-tempo, a definição de vizinho é complexa devido à anisotropia métrica.
A vizinhança de busca é tipicamente definida por um cilindro ou elipsoide centrado em \((\mathbf{s}_0, t_0)\):
Raio Espacial (\(R_s\)): Distância máxima no espaço.
Janela Temporal (\(R_t\)): Intervalo de tempo para trás (e para a frente, na interpolação).
A seleção de vizinhos deve respeitar a forte anisotropia: um ponto muito próximo no espaço mas distante no tempo pode ser menos informativo do que um ponto distante no espaço mas síncrono. O uso da distância espaço-temporal ajustada \(d_{ST}\) (Eq. 7.1) permite definir vizinhanças elipsoidais coerentes com a dinâmica do processo.
7.5.1 Prática no R: Krigagem Espaço-Temporal
A função krigeST do pacote gstat implementa a krigagem espaço-temporal. A sintaxe é análoga à função krige espacial, mas exige objetos da classe ST (como STFDF) e um modelo de variograma espaço-temporal ajustado (como fit_sm da secção anterior).
É possível incorporar covariáveis dinâmicas (que variam no espaço e no tempo), como dados de satélite diários ou saídas de modelos numéricos de tempo. A fórmula do modelo deve incluir essas covariáveis (ex: PM10 ~ temperatura + vento), e o objeto newdata deve conter os valores dessas covariáveis para todos os pontos de predição \((\mathbf{s}_0, t_0)\) (ver Seção 3.13).
Código
sp_grid <-spsample(rural, n =1000, type ="regular") # Grelha espacial baixa resolução para exemplogridded(sp_grid) <-TRUE# Definir Pontos Temporais de Prediçãotime_pred <-as.POSIXct(c("2005-06-01", "2005-06-02"), tz ="UTC")data_pred <-STF(sp = sp_grid, time = time_pred)krig_st <-krigeST(PM10 ~1, data = rural, # Dados observados, obj. STFDFnewdata = data_pred, # Onde prevermodelList = fit_sm, # Modelo ajustadonmax =50) # Vizinhança móvel (espaço-tempo)stplot(krig_st, main ="Predição PM10 (Krigagem ST)")
Dica
Para mais informações, os interessados podem consultar Wikle, Zammit-Mangion, e Cressie (2019) para a prática no R e Cressie e Wikle (2011) e Montero, Fernández-Avilés, e Mateu (2015) para a teoria.
7.6 Validação e Diagnóstico
A validação cruzada Leave-One-Out (LOOCV) clássica (ver Seção 3.7), onde se remove uma observação \(y(\mathbf{s}_i, t_j)\) de cada vez, é frequentemente insuficiente para diagnosticar a robustez estrutural do modelo em contextos espaço-temporais. Em vez disso, Cressie e Wikle (2011) recomendam estratégias que simulam cenários práticos de falha de sensores ou necessidade de previsão futura.
Leave-One-Location-Out (LOLO)
Nesta estratégia, remove-se toda a série temporal de uma localização específica \(\mathbf{s}_i\). O conjunto de treino torna-se:
\[D_{treino} = \{ (\mathbf{s}_k, t_l) : k \neq i, \forall l \in T \}\]
Esta abordagem testa a capacidade do modelo de realizar interpolação espacial da dinâmica temporal completa num local não monitorado, baseando-se apenas na informação dos vizinhos espaciais. É a métrica crucial para redes de monitoramento onde se pretende estimar valores em áreas sem sensores instalados. Um bom desempenho nesta métrica indica que o modelo captura corretamente a estrutura de correlação espacial e a sua evolução temporal.
Leave-One-Time-Out (LOTO)
Aqui, removem-se todas as observações espaciais num instante de tempo específico \(t_j\). O conjunto de treino é:
\[D_{treino} = \{ (\mathbf{s}_k, t_l) : \forall k \in S, l \neq j \}\]
Esta abordagem foca-se na capacidade do modelo de realizar interpolação ou previsão temporal do campo espacial completo. Se \(t_j\) for um instante interior à série temporal, avalia-se a consistência temporal (interpolação). Se \(t_j\) for o último instante observado, torna-se um teste de forecasting puro (previsão de um passo à frente), essencial para aplicações de alerta precoce ou previsão meteorológica.
7.6.1 Métricas de Desempenho
Para uma avaliação completa, as métricas de erro devem ser decompostas para refletir as dimensões espacial e temporal separadamente. Gr"aler, Pebesma, e Heuvelink (2016) sugerem analisar o RMSE espacial (médio ao longo do tempo) e o RMSE temporal (médio ao longo do espaço) para identificar se o modelo falha em capturar a variabilidade geográfica ou a dinâmica temporal.
O RMSE Espacial para a localização \(\mathbf{s}_i\) é dado por:
Esta métrica ajuda a identificar locais onde o modelo tem consistentemente um mau desempenho (ex: devido a efeitos locais não modelados ou outliers espaciais).
O RMSE Temporal para o instante \(t_j\) é definido como:
Esta métrica permite detetar instantes de tempo onde a predição espacial falha globalmente (ex: eventos extremos ou mudanças abruptas no padrão espacial).
Além do RMSE, outras métricas como o Erro Médio Absoluto (MAE), o viés (Bias) e métricas probabilísticas como o Continuous Ranked Probability Score (CRPS) podem ser utilizadas para avaliar a precisão e a calibração das incertezas das previsões.
7.7 Desafios e Abordagens Modernas
A modelagem espaço-temporal enfrenta desafios computacionais expressivos, especialmente com o crescimento exponencial do volume de dados (“Big Data”). Isso impulsionou o desenvolvimento de novas metodologias para além da krigagem clássica baseada em variogramas.
A matriz de covariância espaço-temporal \(\Sigma_{ST}\) tem dimensão \(N \times N\), onde \(N = N_s \times N_t\). Para uma rede modesta de 100 sensores (\(N_s=100\)) medindo diariamente durante um ano (\(N_t=365\)), temos \(N = 36.500\). A inversão desta matriz, necessária para a krigagem, tem complexidade cúbica \(\mathcal{O}(N^3)\), o que rapidamente se torna computacionalmente proibitivo e inviável em termos de memória RAM (Porcu, Furrer, e Nychka 2020).
Para contornar este problema, diversas abordagens foram propostas:
Aproximações de Baixo Posto (Low Rank Approximations): Métodos como Fixed Rank Kriging (FRK)(Cressie e Johannesson 2008) projetam o processo num subespaço de menor dimensão gerado por funções de base, reduzindo drasticamente o tamanho das matrizes a inverter.
Covariância Tapering: Introduz zeros na matriz de covariância para distâncias grandes, tornando-a esparsa e permitindo o uso de algoritmos eficientes para matrizes esparsas (Furrer, Genton, e Nychka 2006).
Métodos de Verossimilhança Composta (Composite Likelihood): Aproximam a verossimilhança total por produtos de verossimilhanças de subconjuntos de dados menores, evitando a inversão da matriz completa (Bevilacqua et al. 2012).
7.7.1 SPDE no Espaço-Tempo
A abordagem de Equações Diferenciais Parciais Estocásticas (SPDE), introduzida por Lindgren, Rue, e Lindstr"om (2011), oferece uma solução elegante e computacionalmente eficiente. A ideia central é representar um Campo Aleatório Gaussiano (GRF) com função de covariância Matérn como a solução de uma SPDE linear fracionária.
No domínio espaço-temporal, a SPDE pode ser estendida para incluir termos de advecção e difusão:
\(\mathbf{v}(\mathbf{s})\) é o campo de velocidades de advecção (ex: vento).
\(\Sigma\) é o tensor de difusão.
\(\mathcal{W}(\mathbf{s}, t)\) é um ruído branco espaço-temporal.
Esta formulação permite modelar fenômenos dinâmicos complexos, como transporte de poluentes, mantendo a esparsidade das matrizes de precisão (inversa da covariância) através de aproximações por Campos Aleatórios de Markov Gaussianos (GMRF). Esta abordagem é implementada no pacote R-INLA (Integrated Nested Laplace Approximation), permitindo inferência Bayesiana rápida para grandes conjuntos de dados espaço-temporais (Blangiardo e Cameletti 2015).
7.7.2 Modelos Dinâmicos Lineares (DLM)
A modelagem de processos que evoluem no tempo e no espaço frequentemente beneficia de uma abordagem dinâmica, onde o estado presente é condicionado ao estado passado. Esta estrutura, formalizada como Modelos de Espaço de Estados (State-Space Models), é particularmente poderosa para lidar com a não-estacionaridade, assimilar dados de diferentes fontes e realizar previsões em tempo real. Ao contrário da krigagem espaço-temporal clássica, que modela a covariância marginal conjunta, os DSTMs focam-se na modelagem da evolução condicional do processo (Wikle, Zammit-Mangion, e Cressie 2019).
A estrutura geral de um DSTM linear Gaussiano compreende duas equações fundamentais:
Modelo de Dados (Observação): Relaciona as observações ruidosas \(\mathbf{Z}_t\) (vetor de dados no tempo \(t\)) com o processo latente verdadeiro \(\mathbf{Y}_t\) e os parâmetros de medição.
Onde \(\mathbf{K}_t\) é a matriz de observação (que pode lidar com dados faltantes ou desalinhados) e \(\boldsymbol{\epsilon}_t\) é o erro de medição.
Modelo de Processo (Evolução): Descreve a dinâmica temporal do processo latente \(\mathbf{Y}_t\), frequentemente como uma auto-regressão vetorial de primeira ordem (VAR(1)).
Onde \(\mathbf{M}\) é a matriz de transição (ou propagação) e \(\boldsymbol{\eta}_t\) é o erro do processo (inovação), que captura a incerteza do modelo dinâmico e possui estrutura de covariância espacial.
O principal desafio na aplicação de DSTMs a dados espaciais densos é a Dimensionalidade. Se \(\mathbf{Y}_t\) representa o processo em \(n\) locais espaciais, a matriz de transição \(\mathbf{M}\) tem dimensão \(n \times n\) (contendo \(n^2\) parâmetros) e a matriz de covariância \(\mathbf{\Sigma}_\eta\) tem \(n(n+1)/2\) parâmetros. Para \(n\) grande, a estimação torna-se inviável.
Redução de Dimensionalidade (Basis Functions):
Em vez de modelar a dinâmica no espaço físico completo, projeta-se o processo num subespaço de menor dimensão gerado por funções de base \(\boldsymbol{\Phi}\). Cressie e Johannesson (2008) introduziram o Fixed Rank Kriging (FRK), onde o processo é decomposto em:
A dinâmica temporal é então modelada sobre o vetor de coeficientes \(\boldsymbol{\eta}\) (de dimensão \(r \ll n\)), tornando a inferência computacionalmente tratável. Gamerman, Lopes, e Salazar (2008a) estenderam esta ideia com a Análise Fatorial Espacial Dinâmica, onde fatores latentes evoluem no tempo e cargas fatoriais espacialmente estruturadas conectam os fatores aos dados.
Incorporação de Dinâmica Física:
Para evitar a “confusão espacial” (colinearidade entre efeitos aleatórios espaciais e covariáveis ambientais) e melhorar a interpretabilidade, Hefley et al. (2017) propõem parametrizar a matriz de transição \(\mathbf{M}\) baseando-se em Equações Diferenciais Parciais (EDPs) de difusão. O processo latente \(u(\mathbf{s}, t)\) evolui segundo:
Esta abordagem permite estimar parâmetros com significado biológico ou físico (como taxas de dispersão) diretamente dos dados observacionais.
Misturas Ponderadas Localmente:
Para lidar com a não-estacionaridade espacial, Stroud, Müller, e Sansó (2001) propuseram modelar a média do processo como uma mistura de regressões lineares locais, onde os coeficientes evoluem dinamicamente no tempo.
Esta formulação flexível permite que a relação entre as variáveis e a dinâmica temporal varie suavemente através do espaço geográfico, capturando comportamentos distintos em diferentes regiões (ex: zonas costeiras vs. interior).
No ecossistema R, pacotes como spTimer(Bakar e Sahu 2015) implementam modelos hierárquicos Bayesianos que utilizam Processos Preditivos Gaussianos (GPP) para lidar com grandes conjuntos de dados (“Big N”), permitindo ajustes de modelos dinâmicos complexos sem estourar a memória RAM. Para abordagens baseadas em SPDE e INLA (discutidas anteriormente), o pacote R-INLA oferece ferramentas para especificar modelos dinâmicos onde a precisão evolui no tempo.
Dica
Para mais informações, os interessados podem consultar Gamerman, Lopes, e Salazar (2008b), Cressie e Johannesson (2008), Hefley et al. (2017), Hannon e Ruth (2001), sendo este último útil para teoria de modelos dinâmicos na vertente não espacial.
Alguns pacotes tem apresentado alguns erros, sugiro ver sempre se houve atualização do pacote.
Os livros de Cressie e Wikle (2011) e Wikle, Zammit-Mangion, e Cressie (2019) tem a teoria e a prática respectivamente.
O artigo Gr"aler, Pebesma, e Heuvelink (2016) tem a teoria, prática, sugiro ver os livros do professor Edzer Pebesma (autor de vários pacotes incluindo gstat)
Bakar, Khandoker Shuvo, e Sujit K Sahu. 2015. “spTimer: Spatio-temporal Bayesian modeling using R”. Journal of Statistical Software 63 (15): 1–32.
Bevilacqua, Moreno, Carlo Gaetan, Jorge Mateu, e Emilio Porcu. 2012. “Estimating space and space-time covariance functions for large data sets: A weighted composite likelihood approach”. Journal of the American Statistical Association 107 (497): 268–80.
Blangiardo, Marta, e Michela Cameletti. 2015. Spatial and spatio-temporal Bayesian models with R-INLA. John Wiley & Sons.
Cressie, Noel, e Gardar Johannesson. 2008. “Fixed rank kriging for very large spatial data sets”. Journal of the Royal Statistical Society Series B: Statistical Methodology 70 (1): 209–26.
Cressie, Noel, e Christopher K Wikle. 2011. Statistics for Spatio-Temporal Data. Hoboken, NJ: John Wiley & Sons.
De Cesare, L, DE Myers, e D Posa. 2001. “Estimating and modeling space-time correlation structures”. Statistics & Probability Letters 51 (1): 9–14.
Furrer, Reinhard, Marc G Genton, e Douglas Nychka. 2006. “Covariance tapering for interpolation of large spatial datasets”. Journal of Computational and Graphical Statistics 15 (3): 502–23.
Gneiting, Tilmann. 2002. “Nonseparable, Stationary Covariance Functions for Space-Time Data”. Journal of the American Statistical Association 97 (458): 590–600.
Gr"aler, Benedikt, Edzer Pebesma, e Gerard Heuvelink. 2016. “Spatio-Temporal Interpolation using gstat”. The R Journal 8 (1): 204–18.
Hannon, Bruce, e Matthias Ruth. 2001. Dynamic modeling. Springer Science & Business Media.
Hefley, Trevor J, Mevin B Hooten, Ephraim M Hanks, Robin E Russell, e Daniel P Walsh. 2017. “Dynamic spatio-temporal models for spatial data”. Spatial statistics 20: 206–20.
Kyriakidis, Phaedon C, e André G Journel. 1999. “Geostatistical Space-Time Models: A Review”. Mathematical Geology 31 (6): 651–84.
Lindgren, Finn, Håvard Rue, e Johan Lindstr"om. 2011. “An explicit link between Gaussian fields and Gaussian Markov random fields: the stochastic partial differential equation approach”. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 73 (4): 423–98.
Montero, José-Marı́a, Gema Fernández-Avilés, e Jorge Mateu. 2015. Spatial and spatio-temporal geostatistical modeling and kriging. John Wiley & Sons.
Pebesma, Edzer. 2012. “spacetime: Spatio-Temporal Data in R”. Journal of Statistical Software 51 (7): 1–30.
Porcu, Emilio, Reinhard Furrer, e Douglas Nychka. 2020. “30 Years of space–time covariance functions”. Wiley Interdisciplinary Reviews: Computational Statistics 13 (2): e1512.
Stroud, Jonathan R, Peter Müller, e Bruno Sansó. 2001. “Dynamic models for spatiotemporal data”. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 63 (4): 673–89.
Wikle, Christopher K, Andrew Zammit-Mangion, e Noel Cressie. 2019. Spatio-temporal statistics with R. Chapman; Hall/CRC.